K8s-11: Interview Questions for K8s
Overview
特性:
自动装箱,自动修复,弹性伸缩,负载均衡,滚动更新,版本回退,密钥和配置管理,存储编排,批处理执行。架构
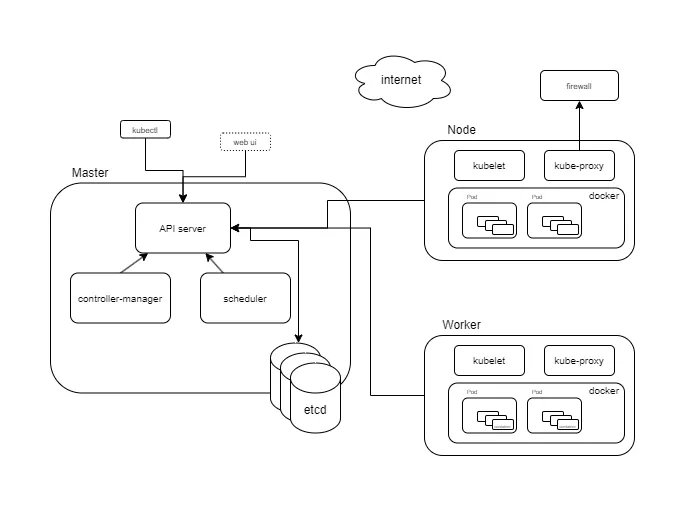
组件
kube-apiserve:提供 HTTP Rest 接口,提供认证,授权,访问控制,API 注册和发现等机制。etcd:键值存储,保存了整个集群的状态。kube-scheduler:负责调度,选择合适的节点进行容器部署。kube-controller-manager:负责维护集群的状态,如故障检测,自动扩展,滚动更新等。kubelet:负责维护容器的生命周期,同时也负责 Volume(CSI)和网络(CNI)的管理。kube-proxy:负责为 Service 提供 cluster 内部的服务发现和负载均衡。Container Runtime:负责镜像管理以及 Pod 和容器的真正运行(CRI)。CoreDNS:负责为整个集群提供 DNS 服务。Ingress Controller:负责集群的入口流量,如 HTTP、HTTPS、TCP、UDP 等流量的转发。Dashboard:提供了一个基于 Web 的 UI,用于容器集群的用户操作。Prometheus:提供了采集集群运行状态的数据,如 CPU、内存、网络等数据。EFK(Elasticsearch、Fluentd、Kibana):提供了集群日志采集、存储、查询和展示的功能。
kubectl:shellcreate:创建资源 get:获取资源 describe:查看资源详细信息 delete:删除资源 edit:编辑资源 apply:应用配置文件 exec:在容器中执行命令 logs:查看容器日志 port-forward:端口转发 expose:暴露服务 run:运行容器 scale:扩容缩容Label:是 k8s 的核心概念,用于标识对象。资源编排shellapiVersion:API版本 kind:资源类型 metadata:元数据 spec:资源规格高可用实现:
keepalived+haproxy
Pod
Pod:是 k8s 的
最小调度单位,是一组容器的集合,共享网络和存储,生命周期短暂。状态
- Pending:
Pod已经被创建,但是容器还未创建成功。 - Running:Pod 中
所有容器已经创建成功,并且至少有一个容器处于运行状态。 - Succeeded:Pod 中所有容器已经创建成功,并且
所有容器已经正常退出。 - Failed:Pod 中所有容器已经创建成功,但是
至少有一个容器异常退出。 - Unknown:Pod 状态无法获取。
- Pending:
生命周期:Pause Container -> Init Container -> App Container (Start、Readiness、Liveness、Stop) -> Termination.
Init Container:用于初始化 Pod 中的容器,Init Container 中的容器会按照
顺序依次执行。Pause Container:Pause Container 是一个特殊的容器,它是 Pod 中
第一个被创建的容器,Pause Container 会创建Pod 的网络命名空间和挂载共享存储卷。Pod重启时,initcontainer会重新执行,但是appcontainer不会重新执行。InitContainer 的spec修改被限制在image字段probe 方式
Exec:在容器中执行命令,如果命令的返回值是 0,则认为健康检查通过。TCPSocket:通过 TCP 连接来检查容器的健康状态,如果连接成功,则认为健康检查通过。HTTPGet:通过 HTTP GET 请求来检查容器的健康状态,如果返回状态码是 200,则认为健康检查通过。
probe 类型
readinessProbe:用于探测容器是否已经准备好接收流量。livenessProbe:用于探测容器是否处于健康状态,如果容器处于非健康状态,则会被自动重启。startupProbe:用于探测容器是否已经启动完成,如果容器未启动完成,则会阻塞容器的启动,直到探测成功或者超时。
Controller
分类:
Replication Controller:用于管理Pod 的副本数量,当 Pod 的副本数量与期望值不一致时,会自动创建或者删除 Pod。Replica Set:是Replication Controller的升级版,支持集合式的selector,支持多种选择器,支持基于Set的滚动更新。Deployment:是Replica Set的升级版,支持滚动更新,支持回滚,支持暂停和继续,支持扩容和缩容。Daemon Set:用于在每个Node上运行一个Pod副本,用于运行一些系统级别的后台任务。StatefulSet:用于运行有状态服务,如 MySQL、Redis、MongoDB 等。Job:用于运行一次性任务,即仅运行一次的任务。Cron Job:用于运行定时任务,即基于时间的任务。Horizontal Pod Autoscaler:用于根据 CPU 利用率自动扩容和缩容 Pod 的数量。
Deployment 回滚策略:保证升级时只有一定数量的 pod 处于
down状态,默认值为25%。RollingUpdate:滚动更新,先创建新的 Pod,再删除旧的 Pod。Recreate:先删除旧的 Pod,再创建新的 Pod。
DaemonSet 应用:
- 运行集群存储 daemon,如 glusterd、ceph。
- 日志收集 daemon,如 fluentd、logstash。
- 监控 daemon,如 Prometheus Node Exporter、collectd、Dynatrace OneAgent。
StatefulSet 特点:
- 稳定的
持久化存储:基于 PVC 的存储卷,重新调度后,pod 仍然可以访问到相同的存储卷。 稳定的网络表示:pod 的 hostname 和 subdomain 是稳定的。基于 headless service 的网络标识,不会因为 pod 的重启而改变。有序的部署和扩展:基于 init container 实现。有序收缩和删除。
- 稳定的
Cron:
给定时间之前没有执行的任务,会被丢弃。创建 Job 的操作是幂等的,即如果 Job已经存在,则不会重复创建。
Service
Service:是一组 Pod 的抽象,提供了 Pod 的负载均衡和服务发现功能。
Service 类型:
ClusterIP:默认类型,用于提供集群内部的服务发现和负载均衡。NodePort:用于将 Service暴露到集群外部,通过NodeIP:NodePort的方式访问 Service。LoadBalancer:用于将 Service 暴露到集群外部,通过Cloud Provider的负载均衡器访问 Service。ExternalName:用于将 Service 映射到集群外部的 CNAME 记录,通过CNAME的方式访问 Service。
Proxy 模式:
userspace:通过iptables实现,性能较差,已经被淘汰。iptables:通过iptables实现,性能较好,但是功能较弱。ipvs:通过ipvs实现,性能最好,功能最强。
Ingress:是对 Service 的
扩展,Ingress 可以提供HTTP和HTTPS的路由、负载均衡、SSL终结等功能。通信方式:
同一个pod中的容器可以通过localhost进行通信。不同pod中的容器可以通过overlay network进行通信。如果 pod 在同一个node上,可以通过veth pair进行通信;如果 pod 在不同的node上,可以通过vxlan进行通信。pod与service之间的通信,通过 iptables 规则进行转发。现在默认使用ipvs进行转发。pot到外网,查找路由表,通过 node(宿主机)的网关转发。宿主网卡完成路由选择后,itables 执行 mapquerade 规则,将 pod 的 ip 地址转换为 node 的 ip 地址,然后发送出去。外网访问pod:通过NodePort或者LoadBalancer进行访问。
网络解决方案
flannel:使用vxlan技术,为 pod 提供 overlay network。etcd保存可分配的ip段。监控 etcd 中 pod 的实际地址,在内存中建立和维护 pod 的路由表。包转发采用udp协议。
Volume
分类
emptyDir:空目录,Pod 被调度到 Node 上时,会在 Node 上创建一个空目录,Pod 中的容器可以访问这个目录。hostPath:宿主机目录,Pod 被调度到 Node 上时,会在 Node 上创建一个宿主机目录,Pod 中的容器可以访问这个目录。nfs:NFS目录,Pod 被调度到 Node 上时,会挂载 NFS 目录,Pod 中的容器可以访问这个目录。configMap:配置文件,将配置文件以文件或者环境变量的方式挂载到 Pod 中。secret:密钥,将密钥以文件或者环境变量的方式挂载到 Pod 中。persistentVolumeClaim:持久化存储,将持久化存储卷挂载到 Pod 中。
emptyDir的生命周期与Pod相同。用作暂存目录,长时间计算崩溃恢复的检查点, 保存内容管理器提取的文件。hostPath: 需要访问容器内部文件,在容器中运行系统级别的任务,如日志收集、监控、存储等。PV:是集群级别的持久化存储,由管理员创建,独立于Pod的生命周期,可以被多个Pod使用。PVC:是用户申请的持久化存储,由用户创建,与Pod的生命周期相同,可以被一个Pod使用。PV 访问模式:
ReadWriteOnce:可以被单个节点以读写的方式挂载。ReadOnlyMany:可以被多个节点以只读的方式挂载。ReadWriteMany:可以被多个节点以读写的方式挂载。
PV 回收策略:
Retain:保留,不会删除 PV,需要手动删除。Delete:删除,会删除 PV,但是不会删除存储卷中的数据。Recycle:回收,会删除 PV,但是会删除存储卷中的数据。Dynamic:动态回收,会删除 PV,会删除存储卷中的数据。
PVC 状态:
Pending:PVC 已经被创建,但是还没有绑定到 PV 上。Bound:PVC 已经被绑定到 PV 上。Lost:PVC 与 PV 的绑定关系丢失。
Scheduler
调度算法:
预选:根据资源需求和资源限制,对所有的Node进行初步筛选,将满足条件的 Node 加入到候选集中。优选:根据调度策略,对候选集中的Node进行打分,将得分最高的Node选为最优Node。
节点亲和性和 Pod 亲和性:
| 调度策略 | 匹配标签 | 操作符 | 拓扑支持 | 调度目标 |
|---|---|---|---|---|
| NodeAffinity | Node | In、NotIn、Exists、DoesNotExist, Gt, Lt | No | node |
| PodAffinity | Pod | In、NotIn、Exists、DoesNotExist | Yes | pod |
| PodAntiAffinity | Pod | In、NotIn、Exists、DoesNotExist | Yes | pod |
Taints: 污点,用于标记 Node,阻止 Pod 被调度到污点的 Node 上。NoSchedule: 不允许调度 pod 到污点的 node 上。PreferNoSchedule: 尽量不要调度 pod 到污点的 node 上。NoExecute: 不允许调度 pod 到污点的 node 上,如果已经调度到污点的 node 上,会被驱逐。
Tolerations: 容忍,用于标记 Pod,允许 Pod 被调度到污点的 Node 上。固定调度:使用
spec.nodeName字段,将 pod 调度到指定的 node 上。
安全策略
认证方式:http token、http base、https。
鉴权方式
AlwaysAllow:允许所有请求。AlwaysDeny:拒绝所有请求。ABAC:基于属性的访问控制,通过配置文件定义策略。RBAC:基于角色的访问控制,通过配置文件定义策略。Webhook:通过 HTTP 回调的方式,将鉴权请求转发到外部服务进行处理。Node:通过 kubelet 对请求进行鉴权。
RBAC:基于角色的访问控制,通过配置文件定义策略。
Role:用于定义资源的访问权限,只能在单个命名空间中使用。ClusterRole:用于定义资源的访问权限,可以在所有命名空间中使用。RoleBinding:用于将Role绑定到用户或者用户组。ClusterRoleBinding:用于将ClusterRole绑定到用户或者用户组。
准入控制:用于在资源被创建或者修改之前,对资源进行校验和过滤。
AlwaysAdmit:允许所有请求。AlwaysDeny:拒绝所有请求。ServiceAccount:校验请求中的ServiceAccount是否存在。NamespaceLifecycle:校验请求中的命名空间是否存在。LimitRanger:校验请求中的资源限制是否合法。ResourceQuota:校验请求中的资源配额是否合法。PodSecurityPolicy:校验请求中的安全策略是否合法。NodeRestriction:校验请求中的Node是否合法。
Helm
Helm:是 k8s 的
包管理工具,用于简化和自动化k8s 应用的部署和管理。Helm 组件:
Helm Client:客户端,用于管理 Chart。Tiller Server:服务端,用于管理 Release。
Chart:是 k8s 应用的
打包格式,包含了 k8s 应用的所有资源定义。Release:是 k8s 应用的
部署实例,一个 Chart 可以对应多个 Release。Repository:是 Chart 的
仓库,用于存储和共享 Chart。Chart 目录结构:
Chart.yaml:Chart 的描述文件。values.yaml:Chart 的默认配置文件。templates:Chart 的模板文件。
Helm 命令:
helm create:创建 Chart。helm install:安装 Chart。helm upgrade:升级 Chart。helm rollback:回滚 Chart。helm list:查看 Release。helm delete:删除 Release。
监控
Prometheus:提供了采集集群运行状态的数据,如CPU、内存、网络等数据。Grafana:提供了数据展示的功能,可以将 Prometheus 采集到的数据以图表的形式展示出来。